중요한 비즈니스 결정을 위해 데이터를 활용하는 것은 모든 분야에서 널리 받아 들여지고 있습니다.
데이터 분석은 비즈니스의 모든 영역에서 수익을 창출하며 수익 창출을 유도하고 수익 결과를 혁신할 수 있습니다. 빅데이터가 보유한 가치를 이해하고 효과적으로 일관되게 결과를 추출할 수 있다면 제품 및 서비스의 품질을 개선하고 고객과 더 잘 이해하며 운영 효율성과 직원 생산성을 높을 수 있습니다.
하지만 이는 큰 변화가 필요합니다.
단지 새로운 기술을 구현하는 문제 뿐만이 아니라, 혁신적이고 근본적으로 다른 비즈니스 모델을 요구합니다. 데이터를 잘 활용할 수 있도록 데이터 전략을 잘 수립해야 합니다.
아래 데이터 기반 조직을 위한 6가지 단계별 지침을 통해 귀사의 데이터 전략을 점검하실 수 있습니다.
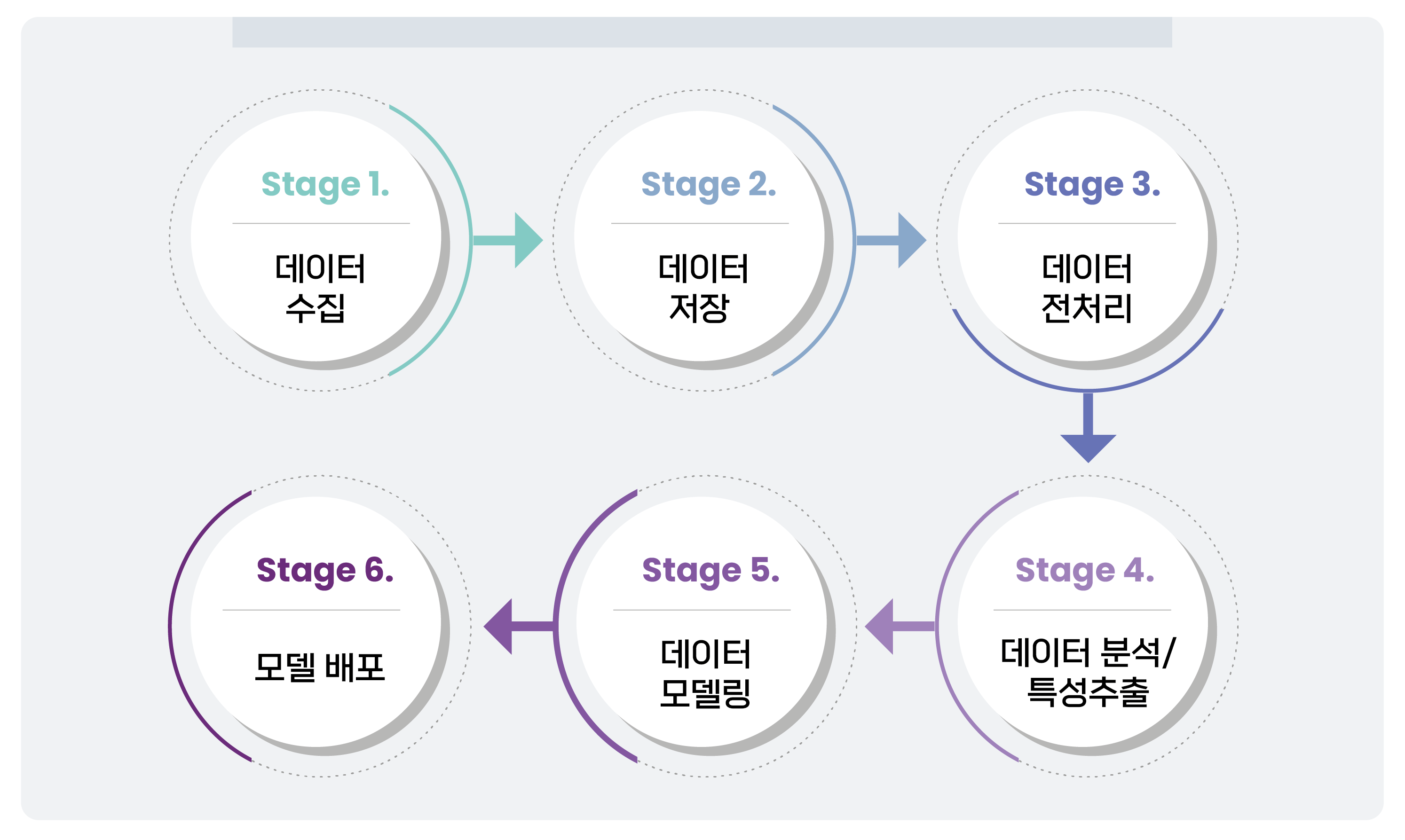
Stage 1. 데이터 수집
Set the Foundation by Collecting the Right Data
데이터 부족으로 어려움을 겪고 있는 조직은 거의 없습니다. 이미 수집하고 있는 엄청난 양의 데이터에 압도되는 것이 일반적입니다. 그러니 비즈니스 문제를 해결하기 위해 적절한 유형의 데이터를 수집하지 못하고 있을 수도 있습니다. 또는 데이터에 엑세스 할 수 없거나 관리하기 어려운 격리된 인프라에 저장할 수도 있습니다.
관련 정보 자산의 포괄적인 인벤토리를 사용하여 데이터 성숙도에 따라 시작할 수 있습니다. 당일 비즈니스 사용 사례로 시작하고 초기 프로젝트가 성공하면 거기에서 확장할 수 있습니다.
데이터 수집 방법은 다양합니다. 기계 시스템의 입력 데이터가 필요하다면 센서를 설치하여 IoT 데이터도 수집 가능하고 실시간 데이터 수집도 가능합니다.
ASK Yourself
Stage 2. 데이터 저장
Making It Usable : Refining the Data
데이터 저장의 유용성을 극대화하기 위해 데이터를 변환해야 하는지 여부와 방법을 확인해야 합니다. 보통 기업은 이 단계에서 걸림돌을 발견하게 됩니다. 특히 데이터 파이프라인이 크거나 복잡한 경우 데이터 파이프라인의 플랫폼을 다시 조정해야 할 수 있습니다.
보유한 데이터 아키텍쳐가 안정적이고 확장 가능하며 거버넌스에 필요한 정책 시행, 강력한 보안 유지 및 규제 등을 준수할 수 있는지 확인이 필요합니다.
ASK Yourself
Stage 3. 데이터 전처리
Enrich and Clean the Data
데이터 전처리 단계는 데이터 분석 과정에서 가장 중요한 단계일 수 있습니다. 귀사의 데이터가 비즈니스 인사이트로 도출되는 과정을 경험할 수 있으며, 데이터기반의 의사결정이 가능합니다. 데이터 사이언티스트와 분석가는 대부분 이 단계에 작업 시간의 80%를 소비한다고 알려져 있습니다.
이 단계에서는 외부 데이터를 가져와 데이터를 더욱 풍부하게 할 수 있습니다. 예를 들어 배송 차량을 운영하고 있는 회사에서 연비 및 가동력을 최적화하기 위해 노력하고 있다고 가정하는 경우, 기존 데이터 정보에 일기예보 및 예측을 추가한다면 도로 사항에 대해 명확한 그림을 제공하고 향후 배송 시간에 대한 정확한 정보를 예측할 수 있는 능력을 향상시킬 수 있습니다.
ASK Yourself
Stage 4. 데이터 분석/특성 추출
Dressing for Success : Aggregating and Labeling Data
비즈니스 인텔리전스 또는 AI(ML/DL) 분석 툴을 적용할 준비가 되었나요?
분석 모델 시나리오를( Metrics 트래킹, user segmentation 등) 설계할 수 있습니다.
이 프로세스는 모델의 반복적인 테스트와 검증을 통해 최적화된 알고리즘을 빌드하는 데 사용하는 프로세스 입니다.
ASK Yourself
Stage 5. 데이터 모델링
Nearing the Top : Simple Machine Learning and Analytics
이제 올바른 소스에서 충분한 데이터를 수집하고 있다는 것을 확인했기 때문에 해당 데이터를 유용하게 활용하고 액세스할 수 있도록 적절한 파이프라인을 마련하고, 해당 데이터의 품질에 확신을 가지고 있으며 데이터 Train 세트를 구축했으며 데이터에서 얻을 수 있는 인사이트를 테스트할 준비가 되었습니다.
머신러닝 알고리즘을 구현하기 시작하면 모델을 테스트하여 작동 여부를 파악할 수 있는 프레임워크를 설정하거나 예기치 않은 상호 작용이 결과에 영향을 미치는지 여부를 파악할 수 있습니다.
통계 분석을 통해 머신러닝 모델의 정확성을 확인할 수 있습니다. 결과 차이가 너무 많은 것을 발견하면, Train 세트에 in-put 데이터를 조정할 수도 있습니다. 추가 데이터의 원본을 통합하면 성능이 크게 향상될 수도 있지만 Hyper-Parameter tunning이 필요한 경우도 있습니다.
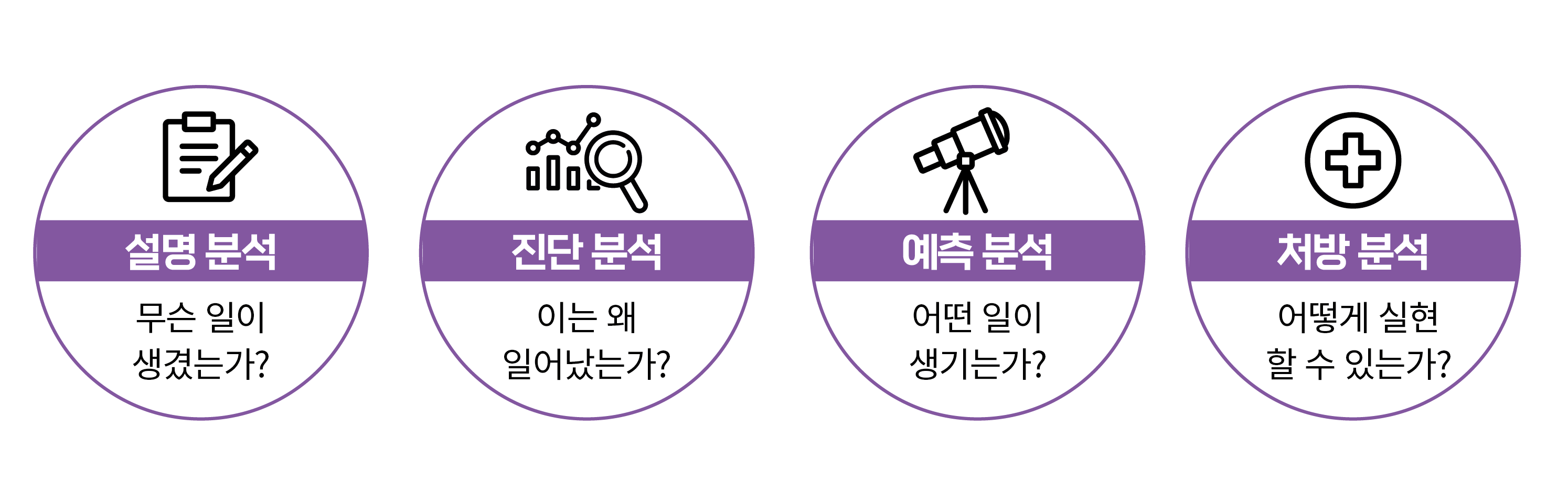
데이터 분석 활용 사례
Stage 6. 모델 배포
Implementing Full-Scale Predictive Analytics
위의 모든 단계를 통과하면 실제 비즈니스 가치를 창출하고 경쟁업체보다 앞서 나갈 수 있는 시스템을 구현할 준비가 되었습니다. 이를 자사 애플리케이션이나 Power BI 시각화 툴 등의 엔드포인트에 연결하여 데이터 인사이트를 도출할 수 있습니다.
당신이 제조업체라면 이제 예측 유지 보수가 발생하기 전에 가동 중지 시간을 선점할 수 있습니다. 소매업체라면 고객 프로필과 쇼핑 트렌드를 모델링하여 구매 결정에 영향을 받을 가능성이 가장 높은 소비자에게 프로모션을 제공할 수 있습니다.







