Innovate data management with a data intelligence platform
Databricks is one of the companies that puts the most emphasis on Data Lakehouse. Databricks was founded by the founder of Apache Spark, which is indispensable in the open-source big data platform ecosystem, and has more than 7,000 customers around the world as a data lakehouse platform. It established a branch in Korea in April 2022.

Databricks is currently putting “Data Intelligence Platform” on the front of its business. Data intelligence platforms use AI models to innovate data management by deeply understanding the semantics of enterprise data. The data intelligence platform is built on Lakehouse, an integrated system that queries and manages all corporate data, but it can automatically analyze data (content and metadata) and how data is used (queries, reports, genealogies, etc.) to add new functions as needed.
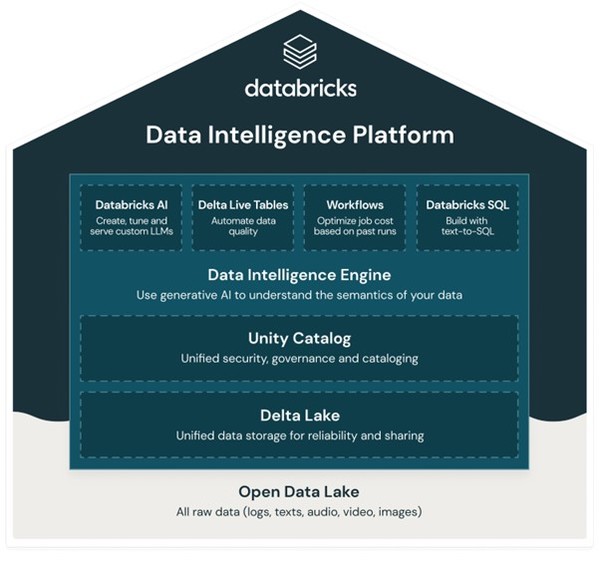


Emphasize “Data Platform,” Expand Investment in Generative AI
Nowflake is also a representative player in the data lakehouse market. Data experts from Oracle gathered and co-founded, and gained fame in 2020 when Warren Buffett invested in public offering stocks in the process of listing on the New York Stock Exchange (NYSE). It established a branch in Korea in November 2021.
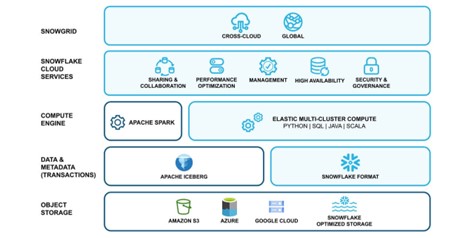
Snowflake started in a cloud data warehouse centered on SQL. As a data warehouse company, it means expanding to a data lake based on the data warehouse rather than adding a data lake to the existing data lake.
Although it is somewhat different from the data lake-based database method, it has the advantage of being able to access all data in the company and utilize the powerful functions of the data warehouse. Snowflake emphasizes the term Cloud Data Platform rather than the term Data Lakehouse.
Snowflake’s CDP solution has four major advantages: △ ease of use △ cost-effectiveness △ connected grid capabilities △ segmented governance. First is ease of use. Snowflake’s CDP is a fully managed service with automated management tasks such as platform construction, upgrades, storage maintenance, and execution engine provisioning. Users can only use it and leave the management to the snowflake side.
Next is high performance and cost-effectiveness. By using Python, SQL, Java, and Scala, structured, semi-structured and unstructured data can be processed into large data volumes, while simultaneously supporting multi-user requests without performance degradation. It continuously provides performance improvement and cost optimization through built-in performance optimization functions.
The third is that it has a grid function connected around the world. Any CSP whose execution environment is AWS, MS Azure, GCP, etc. provides one consistent user experience. Data can be securely connected in multi-cloud and cross-cloud environments to eliminate business silo phenomena, and new business models can be created.
The last is that you can specify granular governance. Data sensitivity, usage, and relationships can be understood as a whole and data can be protected through granular access control policies.
Specifically, a data classification scheme can detect and identify sensitive data and PII data, and object tags can be used to monitor sensitive data about compliance, retrieval, protection, and resource use. In addition, dynamic data masking policies can secure data, and tag-based masking policies can secure data.


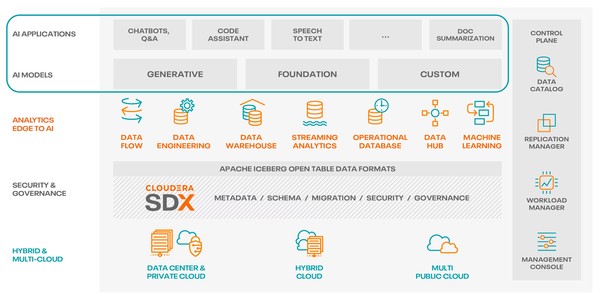
Open Data Lakehouse Offers ‘Cluedera Data Platform’
Claudera, an American company that provides services that support Apache Hadoop and Apache Spark-based SW, is also one of the companies attracting attention in the data lakehouse market. Claudera currently manages 25 exabytes of data for customers just like hyperscalers. Claudera’s data lakehouse core strategy is to provide an open data lakehouse, the Cloudera Data Platform, so that companies can use safe and reliable AI.